Getting Started#
Install LEAF
python -m pip install leaf-framework
Start LEAF
You can start LEAF with a graphical web interface by running:
python -m leaf.start
This will launch a local web server, and you can access the LEAF web interface by navigating to
http://localhost:4242in your web browser. ThisNiceGUI ready to go on http://localhost:4242, http://172.28.36.57:4242, and http://192.168.1.26:4242message indicates that the server is running and accessible from the browser.
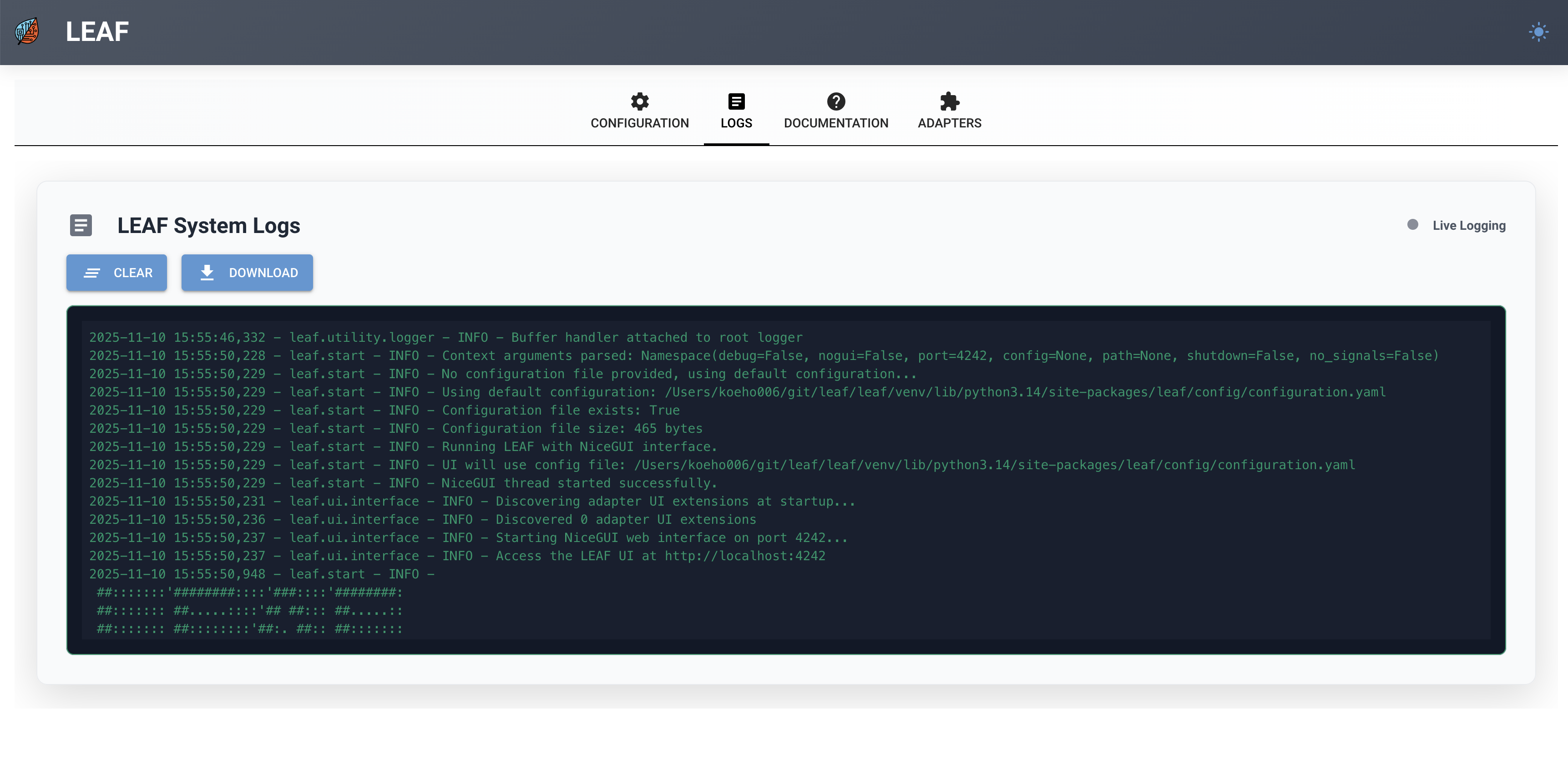
When opening the browser and navigating to the LEAF web interface, you will see the log output by default. This page provides information about what is happening within the system.
Header#
There are several important sections in the header of the web interface:
Configuration: This section allows you to manage and edit the configuration file used to connect your equipment with the output.
Logs: This section provides access to logs generated by the LEAF framework, which can be useful for monitoring and debugging.
Documentation: This section provides access to the LEAF documentation for further guidance and information.
Adapters: This section allows you to manage and install various equipment adapters available within the LEAF framework.
Configuration#
The configuration section is where you define how your equipment adapters will operate. You can edit the configuration that specify the details of your equipment, such as connection parameters, data handling, and output settings. The configuration is written in YAML format, which is easy to read and write.
An example:
EQUIPMENT_INSTANCES:
- equipment:
adapter: Example
data:
instance_id: demo_device
organisation: university_lab
department: research
requirements:
interval: 1
OUTPUTS:
- plugin: MQTT
broker: test.mosquitto.org
port: 1883
# fallback: SQL
# - plugin: SQL
# database: messages.db
# fallback: KEYDB
# - plugin: KEYDB
# host: localhost
# port: 6379
# db: 0
# fallback: FILE
# - plugin: FILE
# filename: local.json
Each configuration file consists of two main sections: EQUIPMENT_INSTANCES and OUTPUTS.
EQUIPMENT_INSTANCES: This section defines the equipment adapters you want to use, along with their specific settings and requirements.
OUTPUTS: This section defines how the data from the equipment adapters will be outputted or stored, such as through MQTT, SQL, KeyDB, or to a local file.
Depending on the adapter chosen, the requirements will differ. On the right there is a dropdown menu available where you can select an example for each of the installed adapters.
At the bottom of the configuration page, there are two buttons available. The Save & Restart button allows you to save any changes made to the configuration file and restart the LEAF framework to apply those changes. The Stop APP button stops the LEAF application which is similar to stopping the app via the terminal using Ctrl+C.
Installing Adapters#
The adapter tab of the web interface provides a list of available adapters that can be installed directly from the interface. You can search for specific adapters and install them with a single click. Once installed, the adapter will appear in the list of installed adapters, and you can manage it from there. When you go to the Configuration page, you will see the installed adapters available for selection to acquire the example configuration. More details on configuring adapters can be found in the Guidelines for defining configuration section.
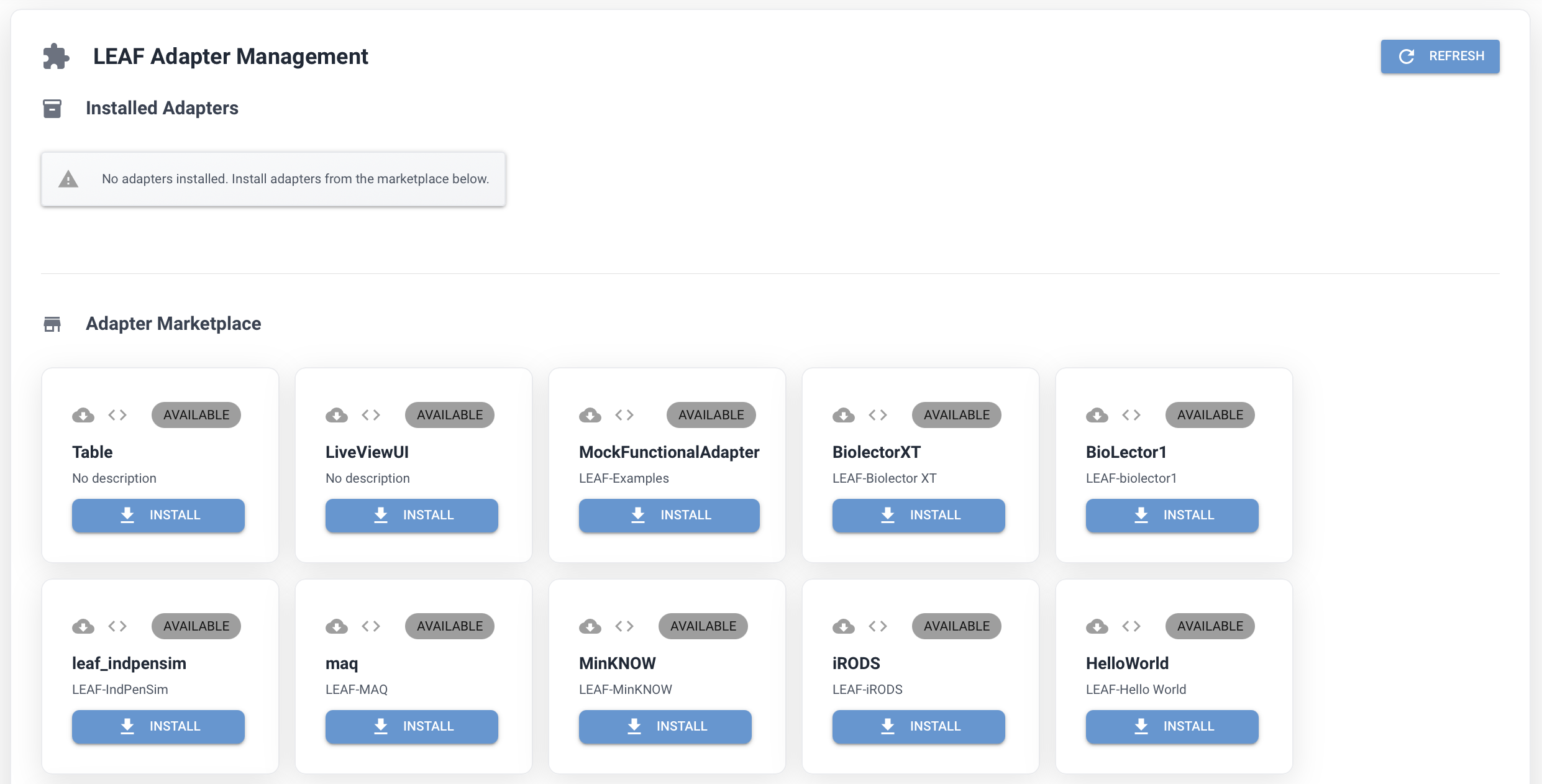
It is also possible to pre-install adapters using the command line interface (CLI) if you prefer not to use the web interface.
For example:
python -m pip install git+https://gitlab.com/LabEquipmentAdapterFramework/leaf-adapters/leaf-example.git
Installs the Example adapter directly from the GitLab repository.
Running EquipmentAdapter#
You can also start LEAF with a specific configuration file directly from the command line. This is useful if you have already set up your configuration file and want to run LEAF without using the web interface.
python -m leaf.start -c config.yaml --nogui
This command starts LEAF using the specified config.yaml file and disables the graphical user interface (GUI) with the --nogui option.
If the adapter has been configured correctly, then the adapter should begin running and monitoring the equipment. If an error occurs, the LEAF adapter system uses custom errors to describe what has occurred. It must be noted that the adapter system will not run if an error occurs during initialisation (errors here are likely fatal and are not recoverable). Still, monitoring errors will not stop the adapter as it is designed to be a continuous monitoring tool.
To see all options available when starting LEAF, you can use the -h flag:
leaf -h
usage: leaf [-h] [--debug] [--nogui] [--port PORT] [-c CONFIG] [-p PATH]
Proxy to monitor equipment and send data to the cloud.
options:
-h, --help show this help message and exit
--debug Enable debug logging.
--nogui Run the proxy without the NiceGUI interface. Useful for headless environments.
--port PORT Port to run the NiceGUI interface on. Default is 8080.
-c CONFIG, --config CONFIG
The configuration file to use.
-p PATH, --path PATH The path to the directory of the adapter to use.
Debugging Adapters#
In some cases, the adapter system may produce errors due to incorrect configuration, genuine fault with the adapter or issue with the equipment. If configuration errors occur, they will be displayed during initialisation, and the program will exit. All of these errors are “AdapterBuildError” errors. These error codes and names are expanded below.
“device.json not found for adapter at …”: The adapter chosen doesn’t have attached metadata, i.e. device.json in the directory.
“adapter_id’ not found in …”: The device.json is present but doesn’t have an adapter_id.
“Adapter for code … not found.”: An adapter adapter_id wasn’t found with the same code as provided in the configuration file.
“Missing instance ID.”: The configuration file provided doesn’t have an instance ID.
“Missing required keys for …”: The required parameters for an adapter haven’t been provided in full. If an error ocurrs during monitoring (usual running of the adapter), the adapter will continue running and attempt to adapt given the type of error. The types of errors are explained below.
InputError: Either the hardware is down, or the input mechanism cannot access the information it should be able to.
HardwareStalledError: The hardware appears to have stopped transmitting information.
ClientUnreachableError: The client OR output mechanism can’t post information. For example, the MQTT broker can’t be transmitted to.
AdapterLogicError: Logic within how the adapter has been built causes an error.
InterpreterError: The adapter interpreter has some faults that cannot be identified without knowledge of the adapter’s specifics.
Guidelines for defining configuration#
When using an adapter, unique information about each physical instance is needed. Each piece may have different identifiers, data paths, and settings. The configuration file provides this individual context by bridging the general adapter code with the specific details of each setup. This configuration allows the adapter system to customise its behaviour for each instance, enabling a single adapter class to be reused across multiple pieces of equipment, each with its configuration.
Equipment Instances#
Each entry under EQUIPMENT_INSTANCES represents an individual EquipmentAdapter instance for a piece of equipment (A single process can support running multiple adapters). This section provides information necessary to distinguish each instance and configure it according to specific needs:
equipment:
adapter: This field specifies the adapter type, which is the equipment ID within the
device.jsonfile of the given adapter (e.g.,ConcreteAdapter1), which is the name of the adapter class. It is needed for adapter discovery. Below, we discuss each aspect of a config file. Due to the config file’s specific nature, some examples for specific adapters are given, denoted with the (EquipmentAdapter specific) tag.data: This field contains identifiers/metadata. It is required for discovery and ensuring uniqueness within the larger network of equipment. If the instance_id is not unique, the program will fail at initialisation.
instance_id: A unique identifier for this equipment instance.
organisation: The organisation where the equipment is based.
department: The department where the equipment is based.
requirements: Defines adapter-specific required operational parameters:
write_file (EquipmentAdapter specific): Specifies the path where data from the equipment will be written.
broker/host (EquipmentAdapter specific): Connection information, such as the host address.
port (EquipmentAdapter specific): The connection port for the host.
token (EquipmentAdapter specific): Code for authentication.
simulation (optional): This nested data is only required for adapters running in simulated mode, which varies by adapter. Not all adapters support simulations.
filename: (EquipmentAdapter specific) A path to a file with simulated data (Note this may change for different adapters).
interval: (EquipmentAdapter specific) The interval in seconds when the simulation will feed the adapter another chunk of data (measurement).
maximum_message_size (optional): If present, it sets the maximum number of measurements that will be transmitted within a single message. The higher this option, the fewer messages will be sent, but each message will be a larger payload.
experiment_timeout (optional): If present, when an experiment is running, and a new measurement hasn’t been taken within this timeout period, the experiment will be stopped. This is used for cases where the lack of measurement data will be due to an error in a given time.
external_input (optional): If present, it will use the external input modules that take data—typically commands—from sources other than the equipment the adapter is designed for. This external source could be another tool for analysing the outgoing data. The external input serves as the entry point to “close the loop”—that is, to feed control signals back into the system based on the analysis. Note that this system is in early development and isn’t fully developed. See (here) for progress. The ExternalEventWatcher names are added as the plugin name and requirements provided below. This process is the same as defining an
OutputModulediscussed below.
Outputs#
Each entry under OUTPUTS represents an OutputModule for transmitting or storing data. Output modules can be chained together through a fallback mechanism, where the next module in the sequence is used if the primary output fails. Like the requirement section within the EquipmentAdapters, most of the fields within an OUTPUTS element are specific to the type of module that is defined to be used.
plugin: This specifies the type of output module, e.g., MQTT, KEYDB, SQL or FILE. The name needs to be the same as the
OutputModuleclass.broker/host (OutputModule specific): Connection information, such as the broker or host address for
MQTTorKEYDBoutputs.port (OutputModule specific): The connection port for the output module.
username/password (OutputModule specific): Credentials for authentication (for secure output modules like
MQTT).fallback: Defines the next output in the chain if the primary output fails. For example, if both previous outputs fail, an
MQTToutput can fall back toKEYDB, which can then fall back to aFILEorSQLoutput.filename (OutputModule specific): Specifies the path to a file where data will be stored locally if other outputs are unavailable (Used in
FILEorSQLoutput modules).
This structure enables flexible data transmission. Primary outputs can be backed up by secondary methods, ensuring data persistence even if one output method encounters issues. This data must be specified within a file known as a “yaml” file. This is essentially a dictionary of keys and values, as seen below.
EQUIPMENT_INSTANCES:
- equipment:
adapter: ConcreteAdapter1
data:
instance_id: example_equipment_id1
organisation: example_equipment_organisation1
department: example_equipment_department1
requirements:
write_file: test/tmp123.csv
- equipment:
adapter: ConcreteAdapter1
data:
instance_id: example_equipment_id1
organisation: example_equipment_organisation1
department: example_equipment_department1
requirements:
write_file: test/tmp.csv
simulation:
filename: tests/static_files/biolector1_full.csv
interval: 10
- equipment:
adapter: ConcreteAdapter2
data:
instance_id: example_equipment_id3
organisation: example_equipment_organisation3
department: example_equipment_department3
requirements:
host: localhost
port: 9501
token: c50dcbbd-fa64-4f9c-98f7-85c39d98c3c2
maximum_message_size: 1
external_input:
plugin: MQTTExternalEventWatcher
broker: localhost
port: 1883
topics:
- test_topic/external_action
OUTPUTS:
- plugin: MQTT
broker: localhost
port: 1883
fallback: KEYDB
- plugin: KEYDB
host: localhost
port: 6379
db: 0
fallback: SQL
- plugin: SQL
filename: local.db
fallback: FILE
- plugin: FILE
filename: local.json
fallback: null